


Nous avons présenté dans un précédent article l’architecture micro frontends. Si vous n’êtes pas familier de ce type d’architecture, je vous conseille vivement de commencer par la lecture de celui-ci. Dans cet article, nous allons aborder plusieurs points de conception liés à ce type d’architecture, notamment sur la communication entre micro frontends et sur la stratégie de tests.
La communication entre micro frontends
Le but de l’architecture micro frontends est de découpler au maximum les différentes parties d’une application. Mais voilà, le plus souvent certaines parties doivent interagir entre elles. Elles doivent pouvoir communiquer.
Comment faire, alors que chaque micro frontends est potentiellement réalisé dans une technologie différente ?
Pour ce faire, on peut utiliser simplement les paramètres d’url, avec toutes les limitations que ça implique. Mais il existe d’autres solutions, plus pratiques, que nous allons aborder ci-dessous.
Attributes + Properties
Dans le cas particulier des Web Components, on peut passer des données avec les attributs directement via le code HTML.
<product-details product-id="1234567890"></product-details>L’exemple utilise via une properties javascript l’identifiant du produit pour afficher les détails dudit produit.
const monWebComponent = document.getElementById("mon-web-component")
monWebComponent.produit = {
id: "1234567890",
name: "Mon produit",
price: 30.5
}
Avantages
L’approche attributes est semblable au transfert de données de composant parent à composant enfant dans les frameworks SPA actuels. C’est donc une façon de faire intuitive pour les développeurs front.
Dans le cas de l’approche properties, certaines librairies permettent même de simplifier l’utilisation de ces dernières en passant les données – même complexes – comme des attributes.
Inconvénients
Le format de données passé en attributes reste assez limité, car n’acceptant que des données sous forme de chaînes de caractères.
Ces données sont directement visibles dans le code, à bannir pour les données sensibles !
Dom / Custom Events
Le DOM est notamment constitué d’une interface orchestrant les events, événements qui ont lieu au sein de la page, qu’ils soient provoqués par l’utilisateur (clic de souris, touche enfoncée par exemple), ou par d’autres éléments (vidéo/audio en pause par exemple).
On peut créer et utiliser ces events pour faire passer des données via l’élément window.
On distingue deux principes :
- window.postMessage()
- Custom Events.
/* emitter.js */
const message = {
type: "important",
content: "Ce message est important",
};
// DOM Event
window.postMessage(message, "https://url-destinataire.fr");
// Custom Event
const event = new CustomEvent("message.important", {
detail: message
});
window.dispatchEvent(event);
/* receiver.js */
window.addEventListener("message.important", handleMessage);
function handleMessage(event) {
// la donnée est accessible dans event.data ou event.detail
}
Il est préférable de privilégier les Custom Events à window.postMessage() dans tous les cas d’usage à l’exception des iframe qui ne permettent que l’utilisation de cette dernière méthode (à cause de leur encapsulation particulière).
La méthode window.postMessage() peut être appelée depuis et vers n’importe quel domaine, il faut être particulièrement vigilant à la réception dans un souci de sécurité applicative.
Avantages
Leur utilisation est simple.
Elle permet d’assurer la réactivité des données entre les micro frontends d’une même page.
Inconvénients
Leur utilisation crée des couplages directs entre les applications émettrices et réceptrices, couplages que l’on cherche justement à éviter.
La gestion des différents events peut devenir rapidement complexe en fonction de leur nombre.
State Management
L’approche composant apportée par les frameworks comme React ou Vue entraîne des dépendances parent-enfants pour le passage de données.
Pour éviter cette complexité, les solutions de state management Redux (pour React), Vuex (pour Vue) et NGRX (pour Angular) permettent à tout composant d’avoir le même niveau d’accès et d’écriture aux données partagées de l’application, rendues indépendantes des composants.
On peut appliquer ce concept sur plusieurs micro frontends : une solution est d’attacher nos méthodes de lecture (selectors/getters) et de modification (actions) au window.
Avantages
La donnée partagée est disponible à tout endroit de l’application, et indépendante de tout micro frontends.
Elle persiste indépendamment des cycles de vie des micro frontends.
Utiliser Vuex, Redux ou Ngrx permet de conserver la mise à jour des données de façon réactive.
Inconvénients
Cette solution (via window) reste néanmoins dangereuse : n’importe qui peut avoir accès à cet élément via la console du navigateur et donc avoir accès à toutes les données communes en lecture et en écriture.
Session Storage / Local Storage / Cookies
La communication de données au sein d’une architecture micro frontends peut aussi passer par les solutions de stockages de données du navigateurs. Il en existe plusieurs, voici les 3 principaux :
sessionStorage: la donnée stockée est accessible uniquement dans un onglet. Elle ne survie pas à la fermeture de celui-ci.localStorage: la donnée stockée est partagée par tous les onglets du navigateur provenant de la même origine. Elle survie au redémarrage de celui-ci, et même du système.cookies: la donnée stockée est accessible par tous les onglets du navigateur provenant de la même origine. La durée de vie est ajustable selon les besoins.
Avantages
Tout comme le state management, l’avantage principal de ces méthodes est de pouvoir avoir accès en lecture et en écriture à des données globales en tout point de l’application et d’être totalement indépendant des changements de pages.
Inconvénients
On retrouve les mêmes inconvénients que précédemment : ces données sont accessibles et modifiables par l’utilisateur directement dans la console, attention donc à la sécurité applicative.
Les objets stockés ne sont qu’au format chaîne de caractères.
Ces données sont « rigides » : une modification n’entraînera pas de mise à jour dynamique dans les applications, mais seulement au rafraîchissement ou au changement de page.
Le volume de données du localStorage est limité par application, selon les navigateurs. De même pour les cookies où la limite est même bien plus basse.
Communiquer avec une API
Si nous avons des équipes distinctes travaillant indépendamment sur chaque micro frontend, quid du développement backend ?
L’avantage des équipes « full-stack » est qu’elles sont propriétaires du développement de leur application, du code visuel jusqu’au développement de l’API, etc.
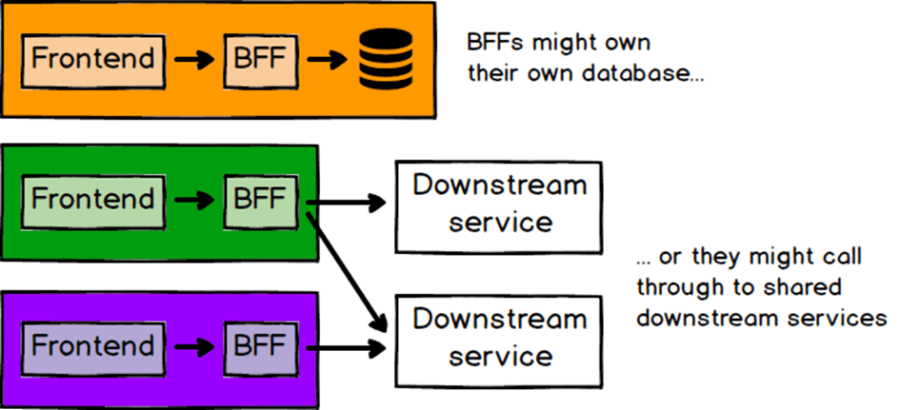
Le modèle à appliquer est le pattern BFF : Backend For Frontend.
Chaque application frontale a un backend dédié dont le but est de répondre uniquement aux besoins de ce frontend (à l’origine ce modèle était destiné à avoir un backend pour mobile, un pour desktop, etc.).
Le BFF peut être autonome avec sa propre logique métier, sa propre base de données, ou être un agrégateur de services.
L’idée est ici que l’équipe qui construit un micro frontend ne devrait pas avoir à attendre que d’autres équipes construisent des choses pour elle (attendre qu’un web service soit développé par l’équipe backend et utiliser, en attendant, des données mockées qui finalement, risquent de ne pas correspondre exactement aux données émises par le service).
Donc, si chaque nouvelle fonctionnalité ajoutée à une micro-interface nécessite également des modifications du back-end, c’est un cas solide pour un BFF, appartenant à la même équipe.
A contrario, si le micro frontend n’a qu’une seule API avec laquelle il échange et que cette API est assez stable, il n’y a peut-être pas beaucoup d’intérêt à créer un BFF.
Comment l’utilisateur d’une application micro frontends doit-il être authentifié et autorisé auprès du serveur ?
Les utilisateurs ne devraient avoir à s’authentifier qu’une seule fois. Par conséquent, l’authentification doit appartenir à l’application conteneur.
L’app conteneur a probablement une sorte de formulaire de connexion, à travers lequel nous obtenons un jeton d’accès. Ce jeton devrait alors appartenir au conteneur et pourrait être injecté dans chaque micro frontend lors de son initialisation.
Enfin, le micro frontend peut envoyer le jeton avec n’importe quelle demande qu’il adresse au serveur, et le serveur peut effectuer les validations requises.
Stratégie de tests
Le modèle d’architecture micro frontends crée de la complexité technique.
Or qui dit complexité technique, dit nécessité de mettre en place un solide harnais de tests automatisés, sans quoi notre superbe architecture risque d’être un fiasco.
Pour rappel les tests automatisés se décomposent principalement en tests unitaires, d’intégration, et end to end (cf. l’article OCTO : La pyramide des tests par la pratique).
- Les tests unitaires vérifient le comportement d’une portion de code totalement ou partiellement isolée de ses dépendances.
- Les tests d’intégration vérifient que plusieurs composants fonctionnent ensemble.
Chaque micro frontend étant une application indépendante, il doit avoir ses propres tests unitaires et d’intégration.
En plus de ces tests, on pourra ajouter des tests de contrats, tests à mi-chemin entre unitaires et d’intégration, indépendants des micro frontends, et qui vont s’assurer que la communication inter-applications est opérationnelle en vérifiant que les interfaces sont bien respectées à l’émission et la réception des données.
Ainsi, s’il y a un breaking change, on sait quel micro frontend est responsable. Enfin les tests end-to-end servent à vérifier le bon fonctionnement d’un parcours utilisateur du début à la fin de sa navigation.
Ce sont ces tests qui vont nous assurer que la cohabitation des micro frontends est cohérente et que l’application est utilisable.
Ces tests sont plus longs à exécuter, moins il y aura d’interactions entre les micro frontends, plus ces tests seront succincts, et donc rapides à exécuter.
Or une modification sur un micro frontend entraîne une modification sur l’application globale : la CI de notre application doit exécuter les tests end-to-end à chaque fois, et on a encore une fois tout intérêt à rendre les micro frontends les plus indépendants possible.
N.B. : le framework de tests end-to-end Cypress a l’avantage de pouvoir passer outre l’encapsulation du Shadow.
Stéphane David
Partager l'article



